By Tim C.
What is this?
Prime Climb is a board game by Dan Finkel where players race two pawns from 0 to 101 using arithmetic. This project strips it down to the core mechanics — no prime cards, just dice and math — and asks: what does optimal play look like?
I solved the game exactly using dynamic programming, then built 5 AI opponents of increasing strength. This page walks through the game theory and the AI designs.
Simplified Rules
- 2 players, 2 pawns each, starting at position 0. Goal: reach 101.
- Each turn: roll two d10 (1–10). Apply one die per move, two moves per turn.
- Operations:
+ - * /applied to your current position with the die value. - Result must be an integer in [0, 101]. Division must be exact.
- Land on an opponent's pawn? They get sent back to 0 (bump).
- First player to get both pawns to 101 wins.
State Space Analysis
The game has a surprisingly tractable state space. A single pawn lives on 102 positions (0–101). Two cooperative pawns with symmetry (since they're interchangeable, enforce p1 ≤ p2) gives102*103/2 = 5,253 states. Small enough to solve exactly.
The full adversarial game (two players, two pawns each) blows up to ~27.6M states — feasible in C but impractical for a browser. So we use exact single-player values as a heuristic for adversarial play.
Single-Pawn MDP
Model the game as a Markov Decision Process. Define V(p) = expected turns to reach 101 from position p, playing optimally. The Bellman equation:
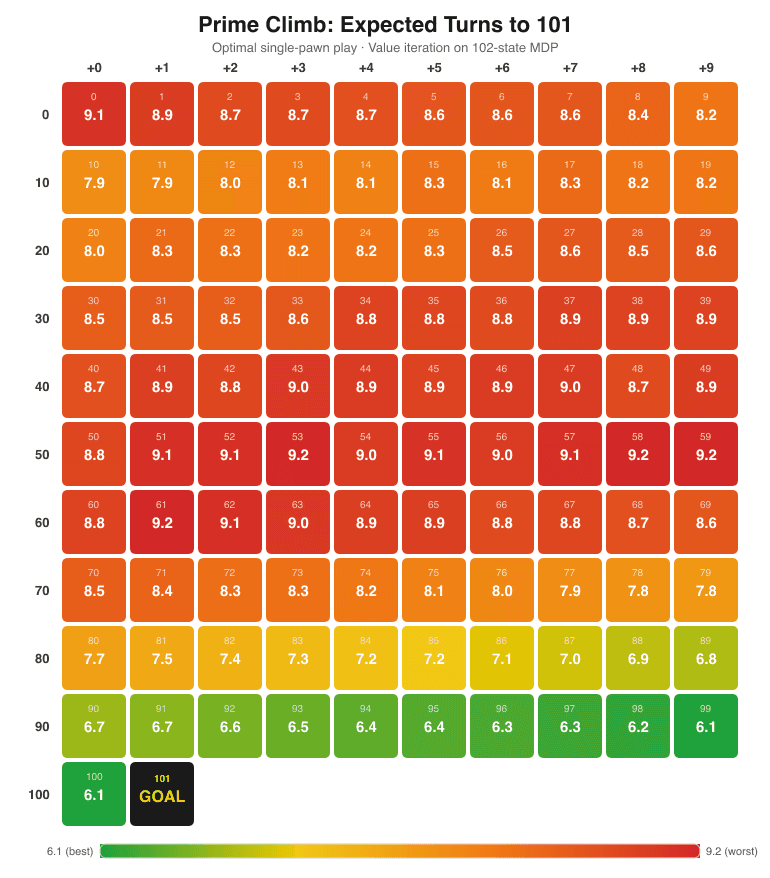
Value iteration converges in ~110 iterations, taking ~30ms. Result: V(0) = 9.07 expected turns from a single pawn at the start.
Key findings:
- 101 being prime dominates the endgame. Even from position 100, it takes ~6.13 turns. You can only reach 101 via addition (no factors in dice range), so you need a net +1 from two dice. Only 19% of rolls from 100 can hit 101.
- The "dead zone" is positions 51–62. These are worse than starting at 0. Too high for useful multiplication (51*2=102, over), too far from 101 for addition. The V-table confirms these are local maxima in expected turns.
- Multiplication is king. Positions with small prime factors (2, 3, 5) enable explosive jumps — 10*10=100 in one step. The optimal policy heavily favors landing on highly composite numbers.
Two-Pawn Cooperative MDP
With two pawns, the state space becomes (p1, p2) with p1 ≤ p2 — 5,253 states. The key new decision: how to split two dice across two pawns. Options include both dice to one pawn, or one die to each.
Result: V(0,0) = 12.27 expected turns — a 32% saving vs. solving each pawn independently (2 * 9.07 = 18.14). This saving comes from dice splitting: when one pawn is in a strong position, you can invest both dice in the weaker pawn.
The solution validates cleanly: V(p, 101) matches the single-pawn V(p) exactly, since when one pawn is done, you're just solving a single-pawn game with the other.
Adversarial Game Theory
The full two-player game is an expectiminimax problem. Define W(my_pawns, opp_pawns) = probability of winning for the active player. The Bellman equation flips perspective after each move:
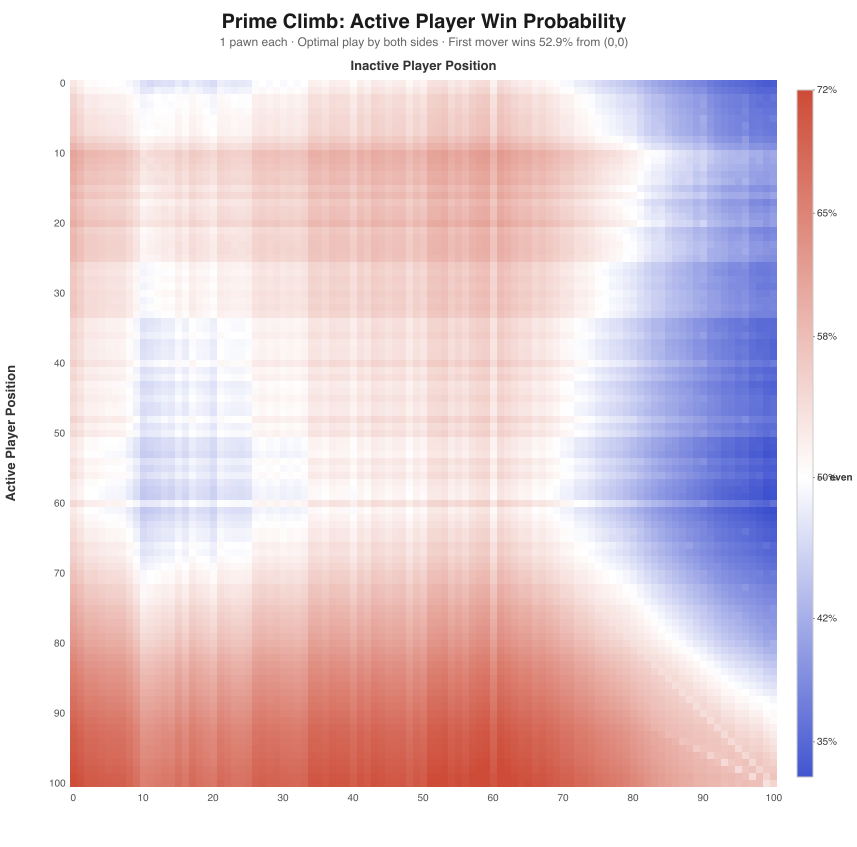
I solved this exactly for 1 pawn per player (10,404 states). The first-mover advantage is 52.9% — significant but not overwhelming. Bumping is strategically devastating: sending an opponent from position 90 back to 0 swings win probability by ~15%.
For 2 pawns each (~27.6M states), exact solution is too expensive for the browser. Instead, the AI uses the cooperative V-table as a heuristic:score = V_coop(opp) - V_coop(me). This captures the race dynamics well and naturally values bumping (sending an opponent pawn to 0 massively increases their V_coop).
Could we solve it exactly?
Yes — it's feasible, just slow. The full 2-pawn adversarial state space has ~27.6M states. Each value iteration sweep needs ~265 billion operations (100 rolls x 96 moves per state). On an Apple M3 Pro running optimized C at ~3–4 Gops/sec, each iteration takes ~70–90 seconds. Convergence requires ~200 iterations, so the full solve is roughly 4–5 hours of compute and ~440MB of RAM. Totally doable as a batch job — the result would be a ~220MB lookup table giving provably optimal play for every possible game state. The current heuristic approach trades that exactness for instant computation in the browser.
AI Difficulty Levels
Five AI opponents, weakest to strongest:
1. Random
Picks a uniformly random legal move. No strategy whatsoever — useful as a baseline to measure how much each smarter AI actually gains.
2. Greedy
Maximizes own pawn advancement: picks the move wheremyResult[0] + myResult[1]is highest. Completely ignores the opponent — no bumping strategy, no positional awareness. Just "go forward."
3. Positional
Hand-crafted evaluation function without the V-table. Scores positions using quadratic proximity to 101, factor richness (positions divisible by small numbers enable multiplication jumps), dead-zone penalties (51–62), goal reachability bonuses (91–100), and explicit bump valuation. Captures domain knowledge without solving the MDP.
4. V-Table
Uses the exact cooperative MDP solution (5,253-entry value table precomputed via value iteration) as a heuristic for adversarial play. Evaluates each move asV_coop(opp) - V_coop(me). Strong because V_coop captures the true expected turns-to-win for any position pair — it just doesn't account for opponent interaction beyond bumping.
5. Aggressive
V-Table base with a bump-hunting overlay. Adds a large bonus for moves that send opponents back to 0, proportional to how far they were — bumping from 95 is devastating (~8 turns of lost progress), from 5 it's marginal. Also adds a small proximity bonus for positioning near opponents (setting up future bumps). Plays noticeably differently from V-Table: it will sacrifice positional advantage to land on an opponent. Slightly weaker overall than pure V-Table (~47.8% head-to-head) because over-indexing on bumps sometimes misses better advancement moves.
AI Matchup Matrix
1,000 games per matchup, averaged across both seat positions (eliminating first-mover bias). Values show the row strategy's win rate against the column strategy.
| Random | Greedy | Position | V-Table | Aggro | |
|---|---|---|---|---|---|
| Random | — | 0.3% | 0.0% | 0.2% | 0.1% |
| Greedy | 99.8% | — | 22.4% | 15.2% | 17.0% |
| Position | 100% | 77.6% | — | 35.5% | 39.0% |
| V-Table | 99.8% | 84.9% | 64.5% | — | 52.3% |
| Aggro | 99.9% | 83.0% | 61.1% | 47.8% | — |
Rankings by average win rate:
- V-Table — 75.4%. The exact MDP solution wins the tournament.
- Aggressive — 72.9%. Close second; bump-hunting trades ~2.5% of raw EV for opponent disruption.
- Positional — 63.0%. Hand-crafted heuristic captures the right ideas but miscalibrates weights.
- Greedy — 38.6%. Advancing fast isn't enough without positional awareness.
- Random — 0.1%. Proves that strategy matters enormously in this game.
Key insight:V-Table beats Aggressive 52.3%–47.8%, showing that the cooperative MDP solution is hard to beat even when extended with explicit adversarial features. The V-table already implicitly captures bump value through the opponent's V_coop term. Over-weighting bumps leads to suboptimal advancement decisions.